Top words and k-means for text clustering
Large text file is clustered into 10 different clusters after top 500 words are identified.
1. Pre-processing
Cleaned continuous text by splitting it into sentences, removing “\n”, and headers.
2. Top-words
Built dictionary of words and sorted them in descending order. Identified top 500 words.
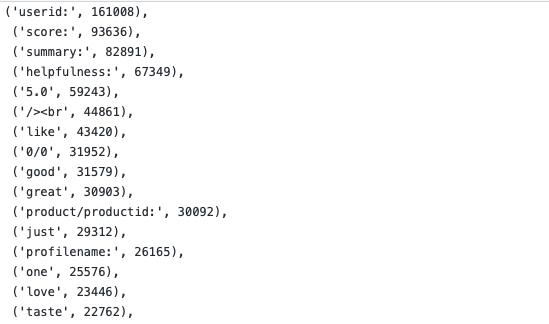
3. Vectorization
Vectorized the words.
4. K-Means Clustering
For k=10, performed k-means using Scikit-learn.
Check out the code here.