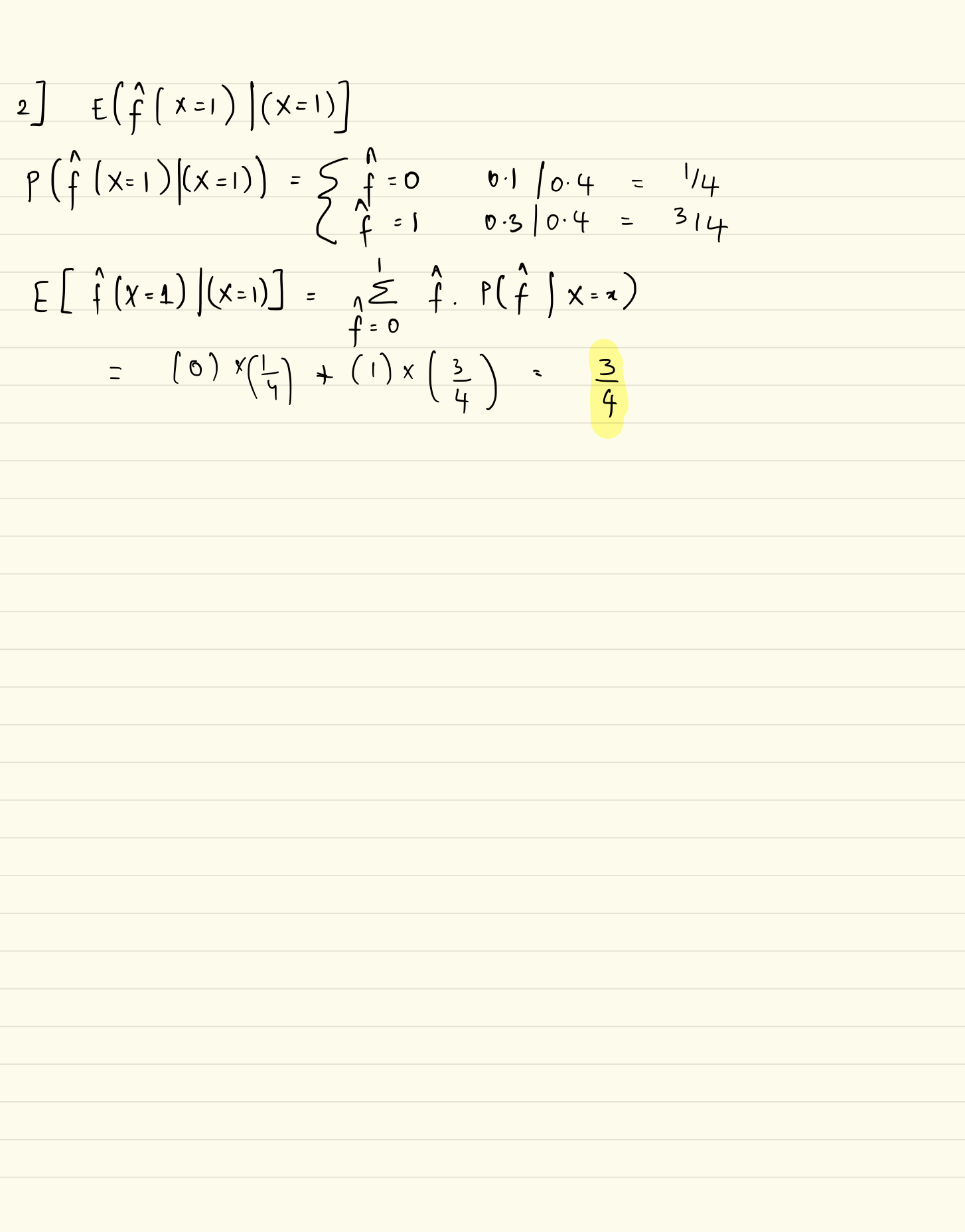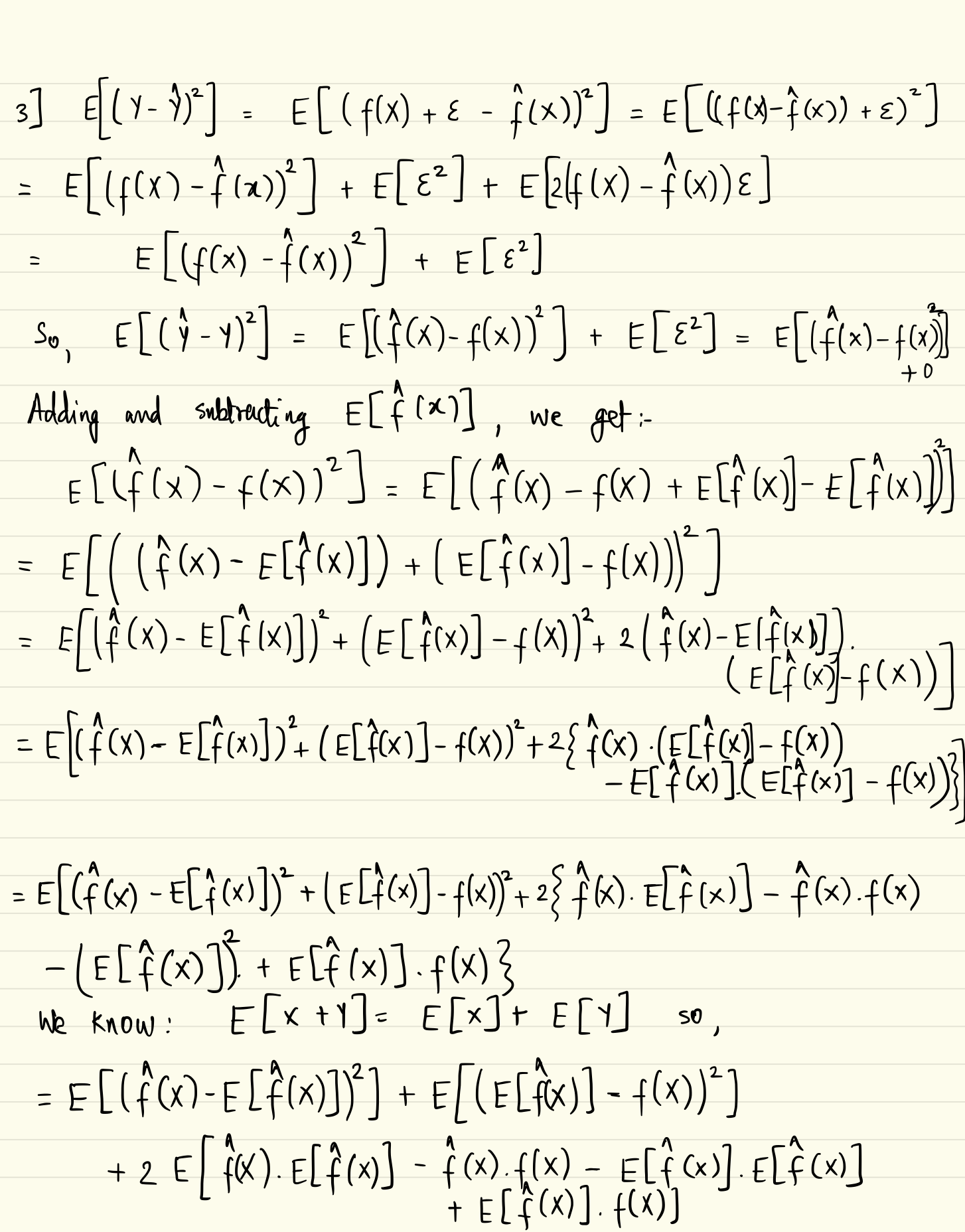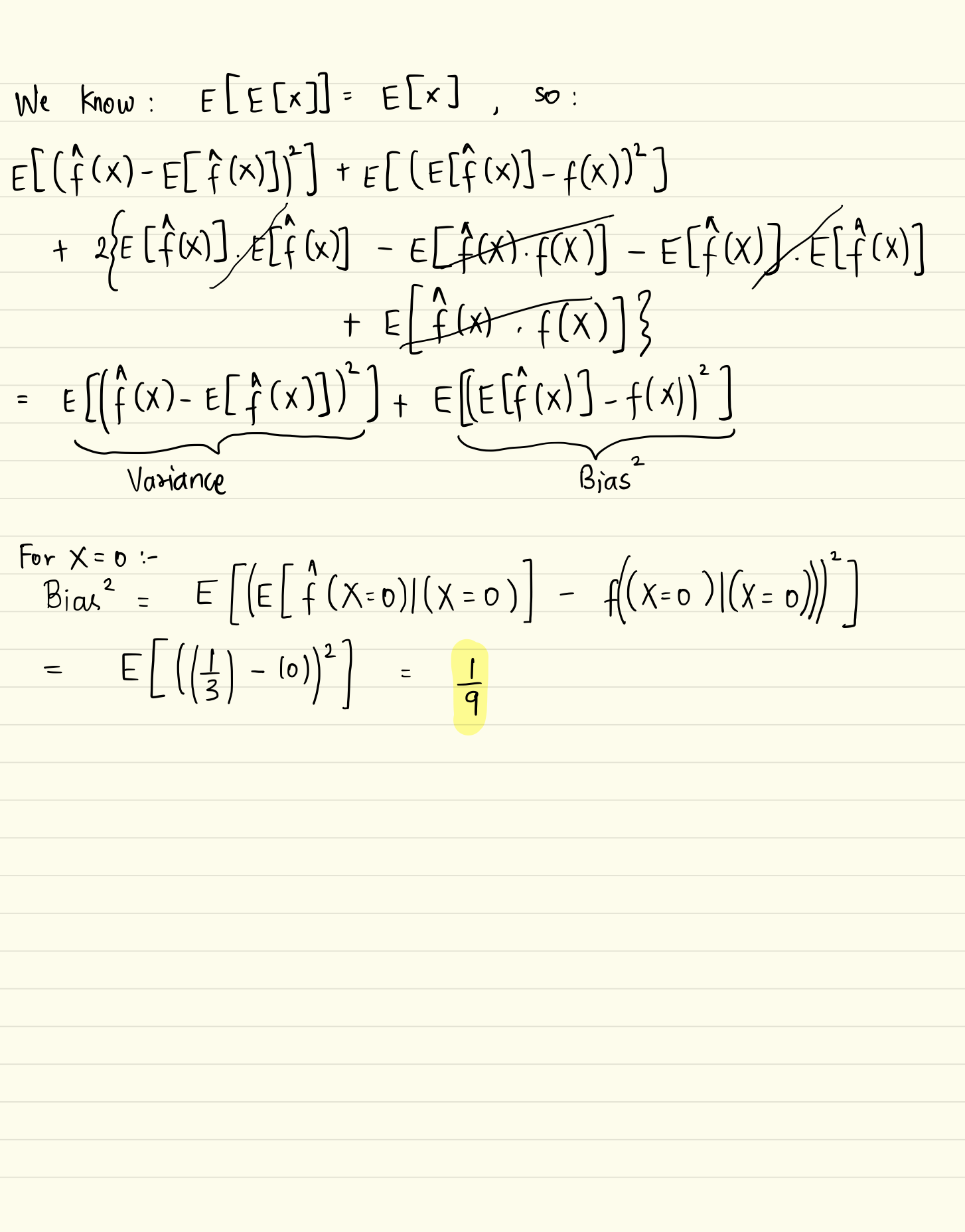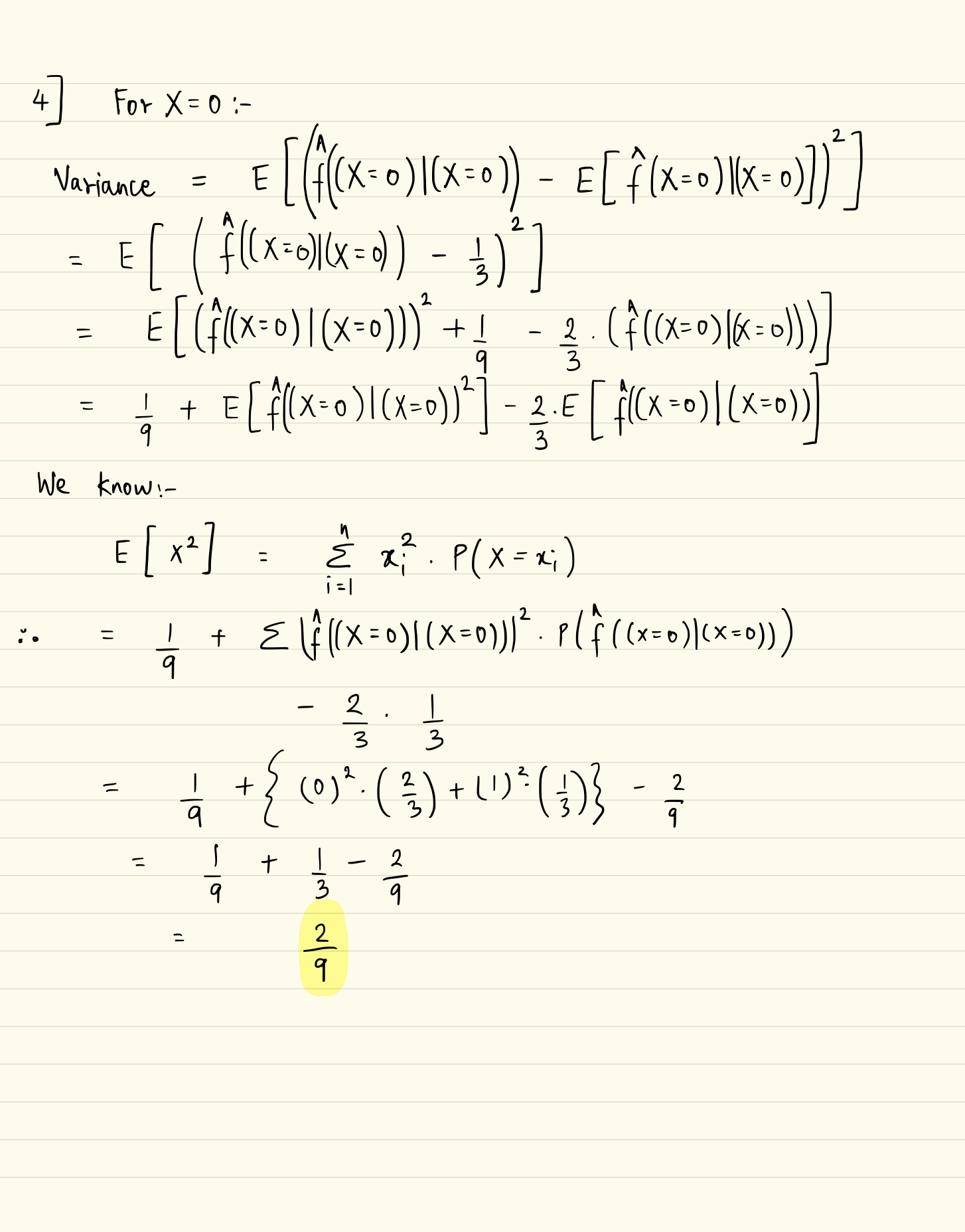Unsupervised Learning and Generalization Performance
Unsupervised Learning
Performed k-means clustering of Spotify’s dataset which contains 13 features related to each song: acousticness, danceability, duration_ms, energy, instrumentalness, key, liveness, loudness, mode, speechiness, tempo, time_signature, and valence.
Step 1: Computed first 2 Principle Components (PC’s).
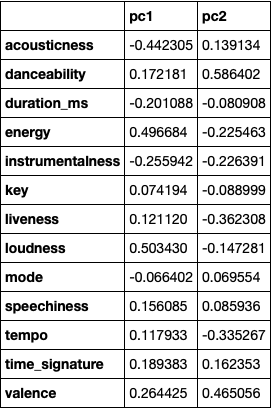
A pipeline was fitted which first standardizes the values w.r.t. Z-score of each metric, and then performs PCA. The factor loadings for each metric for the first 2 PC’s are as follows:
Step 2: Visualized various songs wrt the PC’s.
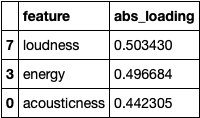
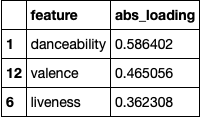
Step 3: Created pandas dataframes of the top-3 metrics w.r.t. each PC.
For PC 1:
For PC 2:
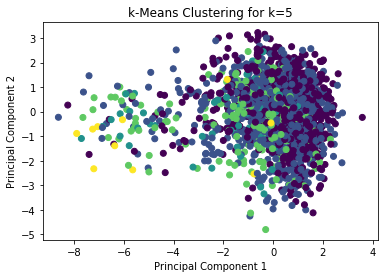
Step 4: Run K-means for 10 PC’s, and 5 clusters.
Generalization Performance